Проблема
Роботы и краулеры не умеют выполнять JavaScript, поэтому если это не “статика”, которая отдается с сервера, а, например, AngularJS, контент не будет загружен. Чтобы crawlers увидел необходимую информацию требуется дополнительная настройка веб-сервер, который проверяет User-Agent. В случае идентификации краулера, вместо того, чтобы показывать простой файл шаблона, например, AngularJS, веб-сервер перенаправляет его на страницу, созданную сервером приложения, которая будет содержать желаемые метатеги, заполненные правильной информацией.
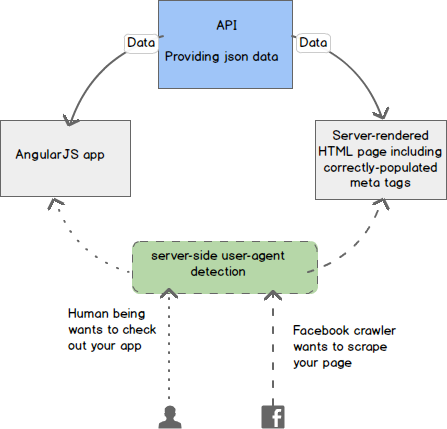
Несколько полезных ссылок для шаринга информации с помощью crawlers (краулеров)
- Блог одного хорошего разработчика из Манчестера, в котором все подробно изложено.
- Документация cтандарта OpenGraph
- Документация по шарингу в Twitter, т.к. он использует свои meta-тэги.
- Документация по настройке nginx
Example in etc/nginx/sites-avaliable/site:
location = /url/:id
{
if ($http_user_agent ~ vkShare|facebookexternalhit|Twitterbot|Facebot|Pinterest|Google.*snippet) {
proxy_pass http://localhost:port/url/$arg_id;
}
try_files $uri/index.html $uri @app;
}
$arg_id - если с параметром ?id=1Example html:
<meta name="twitter:card" content="summary" />
<meta name="twitter:site" content="@name" />
<meta name="twitter:creator" content="@name" />
<meta property="og:description" content="<%=strip_tags(@ob[:content])%>" />
<meta property="og:image" content="<%=@ob.image.url%>" />
<meta property="og:title" content="<%=@ob[:title]%>"/>
<meta property="og:site_name" content="site.com" />
Vladislav Zhurin
Если Вас заинтересовала статья или появились вопросы, оставьте комментарий, а лучше нажми поделиться ;)